此篇 Blog 记录了我在 CS61B 课程中了解到内容,可能在部分章节有点发散,梦到啥查啥了
Project 0 2048
在给出的框架上实现上下左右倾斜的函数,挺简单。
官方的逻辑 好像是分步骤的,先把所有非零元素挤到一边,然后再合并相邻的相同元素,最后再把非零元素挤到一边,逻辑更清晰吧,但我看的是 Hard Mode Project,就没跟着它思路走了。
Linked List
SLList
单链表,只有 next 没有 prev,所以只能从头结点开始往后遍历,不能反向遍历。
1 | class Node { |
DLList
双链表,既有 next 又有 prev,可以正向和反向遍历。
1 | class Node { |
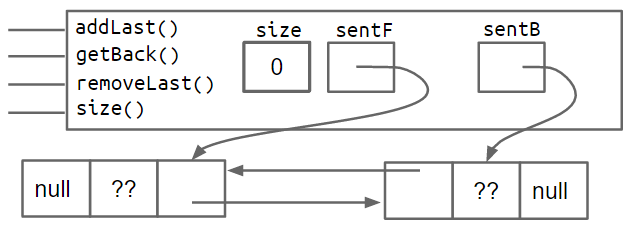
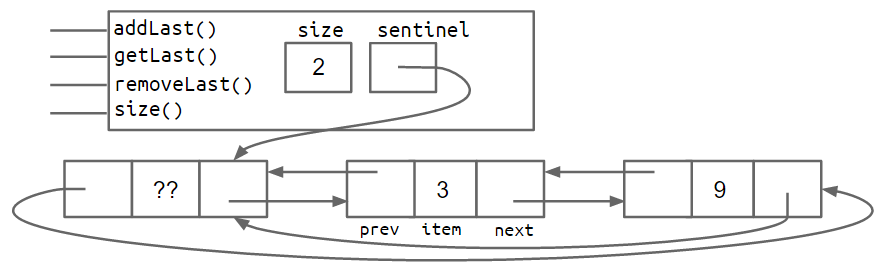
Sentinel Node
我觉得这个设计非常巧妙,学到了。
在链表的首位添加不记录 value 也不计入 size,对应 next 或者 prev 为自身的哨兵节点,只占位,为 Head 节点和 Tail 节点提供了一个的前驱和后继节点,同时应该 next 或者 prev 为自身,可以一直 ->next 或者 ->prev,避免边界条件的问题。
然后还能直接设计成回环,又省一个节点,tql
Array
Java 里面的数组和其他的差不多,不再赘述,这里附上 CS61B 提供的和其他语言的数组的差别
Compared to arrays in other languages, Java arrays:
对比其他语言的数组,Java 数组:Have no special syntax for “slicing” (such as in Python).
没有切片的特殊语法(比如 Python)。Cannot be shrunk or expanded (such as in Ruby).
没有缩小或扩展的能力(比如 Ruby)。Do not have member methods (such as in Javascript).
没有成员方法(比如 Javascript)。
Must contain values only of the same type (unlike Python).
只能包含相同类型的值(不像 Python)。
ArrayList
Linked List 的缺点是访问元素需要从头结点开始遍历,时间复杂度是 O(n),而 Array 可以通过索引直接访问,时间复杂度是 O(1)。
但 Linked List 可以随意扩容,而 Array 一旦创建就不能变更大小。
因此封装一个 ArrayList 类,内部使用 Array 来存储元素,当 Array 满了之后,创建一个更大的 Array,把原来的元素 copy 过去;当 Array 内元素被删除了很多之后,创建一个更小的 Array,把原来的元素 copy 过去。
逻辑非常简单,只是需要考虑合适的扩容和缩容的时机,避免频繁的扩容和缩容导致性能问题。
顺便参考了下常见语言的实现:
Go 的 slice 扩容会在小容量(小于 256)下翻倍,大容量下平滑增加 25%。但并不会缩容。
参考自 runtime/slice.go
nextslicecap 源码
1 | // nextslicecap computes the next appropriate slice length. |
Disjoint Sets
不相交集,提供 connect(a, b) 和 isConnected(a, b) 两个操作,支持合并两个集合和查询两个元素是否在同一个集合中。
最简单的实现是 List<Set<Integer>> 通过遍历列表,查询元素是否在相同的集合中,时间复杂度 O(n)。
Quick Find
将每个元素映射到一个 id,id 相同的元素在同一个集合中。
将每个元素存储到列表中,索引为元素值,值为元素的 id。
这样 isConnected(a, b) 操作只需要比较两个元素的 id 是否相同,时间复杂度 。
但 connect(a, b) 操作需要遍历整个列表,将所有值为 id_a 的替换为 id_b(或者相反),时间复杂度 。
Quick Union
Qucik Find 的思路是修改所有 id_a,是扁平的。
假如每个集合是一棵树,那么 connect(a, b) 操作只需要先找到 a 和 b 的根节点,然后将 a 的根节点连接到 b 的根节点即可(或者相反),时间复杂度 , 是树的高度。
这样 isConnected(a, b) 操作需要先找到 a 和 b 的根节点,然后比较根节点是否相同,时间复杂度 。
但是如果持续将一个集合的根节点连接到另一个集合的根节点,可能会导致树的高度变得很高,最坏情况下退化成链表,时间复杂度变成 。
例如 connect(1, 2), connect(2, 3), connect(3, 4),最终变成 1 -> 2 -> 3 -> 4。
Weighted Quick Union
树的高度决定了 connect 和 isConnected 的性能,所以决定 a 的根节点连接到 b 的根节点还是相反,应该根据树的大小来决定,较小的树连接到较大的树,这样可以保证树的高度尽可能小,这样时间复杂度为 。
例如 connect(1, 2), connect(2, 3), connect(4, 5), connect(5, 6), connect(2, 5), 最终变成
1 | 2 (大根) |
而不是
1 | 3 |
Path Compression
在 isConnected(a, b) 操作中,找到 a 和 b 的根节点的过程中,必须遍历整个路径。在遍历到根节点后,将路径上的所有节点直接连接到根节点,这样可以进一步降低树的高度,时间复杂度为 ,在长期行为上接近常数。
Binary Search Tree (BST)
BST 是一种特殊的二叉树,满足以下性质:
- 每个节点的值都小于其左子树中所有节点的值
- 每个节点的值都大于其右子树中所有节点的值
Insert
从根树往下查询插入值,如果不存在,已经到达叶子节点了,就选择左右插入新节点。
时间复杂度为 , 是树的高度,最坏情况下退化成链表,时间复杂度变成 。
Search
从根树往下查询目标值,如果大于当前节点值,就往右子树查询;如果小于当前节点值,就往左子树查询;如果等于当前节点值,就找到了。
时间复杂度为 , 是树的高度,同样最坏情况下退化成链表,时间复杂度变成 。
Delete
删除比较麻烦,分三种情况
无子节点
直接删除节点即可。
有一个子节点
将子节点直接连接到父节点上,删除当前节点即可。
有两个子节点
显然删除后只有一个节点能够代替当前节点的位置,应该选择右子树中最小的节点(或者左子树中最大的节点)来代替当前节点的位置,这样可以保证 BST 的性质不被破坏。
因为在数值上与当前节点的值的差的绝对值最小的节点,才能在不改变大小关系下替换当前节点,其一定是左子树的最右边(小的里面最大的)或者右子树的最左边(大的里面最小的)的节点。
B Tree
树的高度决定性能,如果树的左右子树高度相同,那么就是平衡树,高度最低。
树不止于二叉,可以有多个叉。
增加时先塞入叶子节点,如果叶子节点满了,就将中间值向上弹,以此类推,绝不在向下增加高度。
Red-Black Tree
我觉得红黑树在这些里面是最难理解的
用二叉树来实现 B Tree,具体的说,CS61B 里面的是左倾红黑树。
Left Leaning Red-Black Tree
规则有:
- 只有左子节点可以是红色
- 没有连续的红色节点
- 每个叶子节点到根节点的黑色节点数量相同
- 是 2-3 树
Rotation 旋转
旋转有左旋 rotateLeft 和右旋 rotateRight。
rotateLeft
对于下面这个树
1 | 1 |
可以通过 rotateLeft(1) 变成
1 | 2 |
将 1 用 root 表示,2 用 newRoot 表示,则过程是先将 root.right 指向 newRoot.left,然后将 newRoot.left 指向 root,最后将 newRoot 返回作为新的子树的根节点。
1 | private Node rotateRight(Node root) { |
rotateRight
对于下面这个树
1 | 2 |
可以通过 rotateRight(2) 变成
1 | 1 |
将 2 用 root 表示,1 用 newRoot 表示,则过程是先将 root.left 指向 newRoot.right,然后将 newRoot.right 指向 root,最后将 newRoot 返回作为新的子树的根节点。
1 | private Node rotateLeft(Node root) { |
Insert
首先像 BST 一样插入节点,注意是红色的,因为不向下增加高度,然后进行自下而上修复。
Case 1 右红节点
违反了只有左子节点可以是红色的规则,进行左旋转。
1 | 2 add(R4) 2 rotateLeft(3) 2 |
Case 2 连续左红节点
违反了没有连续的红色节点的规则,进行右旋转。
1 | 2 add(R3) 2 rotateRight(5) 2 flipColors(4) 2 |
Case 3 两个红子节点(4-node)
违反了只有左子节点可以是红色的规则,将该节点和子节点的颜色反转模拟分裂。
1 | 2 add(R5) 2 flipColors(3) 2 |
1 | private Node insert(Node root, int key) { |
(True) Red-Black Tree
红黑树的规则不要求只有左子节点可以是红色的,而是允许左右子节点都是红色的,但同样不允许连续的红色节点。
- 节点是红色和黑色
- NIL 节点是黑色的
- 没有连续的红色节点
- 从根节点到 NIL 节点的每条路径上的黑色节点数量相同
可以补充第五条
- 根节点是黑色的
红黑树是一棵 2-3-4 树的二叉树表示,一棵红黑树可能对应多棵 2-3-4 树,但一棵 2-3-4 树只能对应一棵红黑树。
Insert
插入新节点总是红色的,首先像 BST 一样插入节点,然后进行自下而上修复。
-
父节点是黑色节点 -> 不需要修
-
父节点是红色 -> 违反了没有连续的红色节点的规则,按照以下三种情况修复
假设待插入节点为 ,父节点为 ,祖父节点为 ,叔叔节点为 。
Case 1
父节点的兄弟节点是红色
1 | g(B) g(R) |
直接翻转 和 的颜色,变为黑色,翻转 的颜色,变为红色。此时 的父节点 变为黑色,不再连续红色了,但可能 和它的父节点连续红色了,所以继续向上修复。
Case 2
父节点的兄弟节点是黑色,且父节点的方向和待插入节点的方向相反
1 | g(B) g(B) |
旋转父节点 ,将父节点 变为 的子节点,此时方向一致,继续按照 Case 3 修复。
Case 3
父节点的兄弟节点是黑色,且父节点的方向和待插入节点的方向一致
1 | g(B) p(B) |
旋转祖父节点 ,将父节点 变为新的根节点,交换 和 的颜色,修复完成。
Delete
待删除节点 可能在任意位置,分以下情况:
-
若 有两个子节点,则像 BST 一样找到右子树的最小节点 ,将 的值复制到 上,然后删除 。此时 肯定没有左子节点,可能有右子节点。
-
若 只有一个子节点,由于黑高一致而另一侧没有节点黑高为 0,可知 不能为黑色必为红色,又因为没有连续红,所以 必为黑色,则将 的颜色改为黑色,替换 的位置即可。
-
若 没有子节点,如果 是红色或者是根节点,直接删除即可;如果 是黑色的非根节点,则会导致黑高不一致,需要进行修复。
以下是 _delete_fix 的逻辑,比较复杂。
首先假设待删除节点 是黑色的非根节点,且没有子节点,其父节点为 ,兄弟节点为 ,兄弟节点的左右子节点为 和 。
1 | p |
那么在删除了节点 之后,对于父节点 的左右黑高一致而言, 所在的一侧黑高 -1。
要修复黑高平衡,可以借调一个兄弟侧的黑色节点过来,且在兄弟侧找到红色节点变黑补充借调的黑色节点,使得两侧黑高一致。
区分出以下四种情况:
Case 1
兄弟节点 是红色的
1 | p(B) s(B) |
兄弟节点 是红色的,无法借调黑色节点过来补充黑高,需要先将兄弟节点 进行左旋,将兄弟节点变为黑色,变为剩下三种 Case。
注意:这里的旋转后,兄弟节点由 变为了 ,而不是 。
Case 2
兄弟节点 是黑色的,且兄弟节点的两个子节点 和 都是黑色的
1 | p(?) p(?) |
将兄弟节点 变为红色,使得兄弟侧的黑高 -1,此时满足黑高平衡,但可能与父节点 连续红色了。
左右两侧都黑高-1,达到了局部平衡,但影响了全局平衡。
如果父节点 是黑色的,继续向上修复;如果父节点 是红色的,则将父节点 变为黑色,修复完成。
Case 3
兄弟节点 是黑色的,且兄弟节点的左子节点 是红色的,右子节点 是黑色的
1 | p(?) p(?) |
兄弟节点底下有红色节点,但是在兄弟节点的内侧,需要将 右旋,变为 #Case 4
Case 4
兄弟节点 是黑色的,且兄弟节点的右子节点 是红色的(注意,它不要求左子节点为黑色,只需要右红子节点)
1 | p(?) s(?) |
不同于 #Case 3,兄弟节点底下有红色节点,并且在兄弟节点的外侧,可以从兄弟节点旋转一个黑色节点到己侧,增加己侧的黑高,同时将兄弟节点的右子红节点设置为黑色,保持兄弟节点的黑高不变。
此 Case 确实完成了借调,在保持全局黑高平衡的前提下,修复了局部黑高不平衡的问题。
1 | p(B) s(B) |
可以发现,右侧的黑高 -1 了,导致黑高不平衡。
Thinking
这里面的设计很巧妙…但是看 OIWiki 红黑树 的时候,我看了好几遍也没看懂,配合代码和 AI 食用更佳。
以下是我自己的理解的记录,不保证正确。
我参考了美团的知乎专栏 红黑树深入剖析及Java实现 里面关于“借调”这个概念的,觉得很形象。他首先从维护黑高平衡入手,删除一个黑色节点之后,要不增加己侧的黑高,要不减少兄弟侧的黑高,来达到局部平衡。
Case 4 增加己侧的黑高,从兄弟侧借调一个黑色节点过来,减少了兄弟侧的黑高,则需要兄弟侧有一个红色节点来变色补充借调的黑色节点,保持兄弟侧的黑高不变,不影响全局平衡的同时维护局部平衡。
Case 2 减少了兄弟侧的黑高,则局部平衡,但全局不平衡了,继续向上修复。
Case 1 和 Case 3 都是为了调整到其他 Case 的情况。
只平铺着看四种 Case 没理解,看整个流程才能理解。=-= 不过我也是太菜了
可以参考 OIWiki 红黑树 参考代码 的实现。
我的参考实现在这 https://gist.github.com/z0z0r4/58dd119257f48015bb1de02ca1b4ad5f,应该能用(?)
HashTable
这里的哈希表通过定长数组实现,容量和哈希函数决定了哈希表的性能。
选择一个合适的哈希函数,产生对应的 hashCode,然后通过 hashCode % capacity 计算出元素在数组中的索引位置,如果位置被占用了,就通过链表或者开放寻址等方式解决冲突。
以链表法为例,哈希表的最差效率由最长的链决定。
扩容
可以根据负载因子 来决定是否扩容,Java 的默认负载因子是 0.75,当负载因子超过 0.75 时,就进行扩容,通常是将容量翻倍。
注意,扩容后需要重新映射所有元素的位置,因为容量变了,hashCode % capacity 的结果也会变。
1 | class HashTable { |
然而参考 Python 的 dict 的实现 dictobject 还有更多优化空间。
Python 的 dict 将哈希表分为两个数组,一个是 indices 数组,存储哈希值和元素在 entries 数组中的索引;另一个是 entries 数组,存储实际的键值对。
前者和上面的哈希表设计差不多,后者则是一个紧凑的数组,存储实际的键值对,它的每个元素大小远大于一个 int 索引(),将索引和数据分离能大幅节省空间。
同时,dict 还有不同于如上的哈希表设计,使用开放寻址法解决冲突,具体来说是线性探测(linear probing),当发生冲突或者与查询 key 不符时,继续向后查找下一个空位,直到找到为止,具体如何找到下一个空位可以参考以下源码。
首先 perturb = hash,然后每一次循环:
-
perturb >>= 5;(不断消耗高位哈希值) -
i = (i * 5 + perturb + 1) & mask;(计算下一个索引位置)
其中通过 perturb 来减少聚集现象,即相同低位哈希值的元素聚集在一起,导致冲突频发,利用了哈希值的高位比特来引入随机性。
1 | /* Internal function to find slot for an item from its hash |
当然这个机制对稀疏性要求也不低,Python 中定义的是 #define USABLE_FRACTION(n) (((n) << 1)/3),当哈希表的使用率超过 2/3 时,就进行扩容。
同时对于被删除的元素,贸然设置为空会导致查询链断裂,因此会在 indices 对应位置上,设置为一个特殊的 DUMMY 标记,表示该位置曾经被占用过,但现在已经被删除了,这样查询时遇到 DUMMY 标记时会继续向后查找。
扩容的时候也需要重新映射所有元素的位置,因为容量变了,hashCode % capacity 的结果也会变,在此之中会重新压实 entries 数组,将所有 DUMMY 重新设置为空。
具体来说,ma_used 是键值对的数量,dictresize 中 newsize = max(PyDict_MINSIZE, ma_used * 3); 来决定新的容量,同时 estimate_log2_keysize 找到第一个大于等于 newsize 的 作为最终的容量。
初始容量是 PyDict_MINSIZE 为 8。
看起来这个设计改进于 [Python-Dev More compact dictionaries with faster iteration]
(https://mail.python.org/pipermail/python-dev/2012-December/123028.html),这里还产生了个非常有用的副作用————字典的迭代顺序和插入顺序一致了,entries 数组的顺序就是插入的顺序。
Heap
以下部分补充是在学习 CLRS 的时候写的,未来可能单开文章,暂时放这里。
堆是一棵树,其每个节点都有一个键值,且每个节点的键值都大于等于/小于等于其父亲的键值,大于的是小根堆,小于的是大根堆,以下内容都是大根堆。
以下实现是二叉堆。
二叉堆实现
1 |
|
Tree Representation
一般的树通过 Node 类实现,用指针指向下一个节点,而堆通过保证完全二叉树的性质,可以通过数组来实现,父节点和子节点之间的关系可以通过索引计算出来。
一般的树也可以用数组表示,如果不介意空间利用率低的话,每一层都需要 个位置来存储节点,但显然完全二叉树才能充分填满数组。
关于计算索引(以 0 开始):
- 父节点索引:
- 左子节点索引:
- 右子节点索引:
粗略计算
首先假设节点为的索引为 ,则该层之前有 个节点,其中 是该层的层数(从 0 开始),其在该层的偏移量从 0 开始是 ,因此
父节点的层数为 ,父节点在该层的偏移量为 (向下取整),因此父节点的索引为
代入 ,得到
所以父节点索引:
左子节点的层数为 ,左子节点在该层的偏移量为 ,因此左子节点的索引为
右子节点为
Swim up
上浮指的是将可能打破堆性质的节点向上交换,直到符合性质。
Sinking
下沉同样也是和上浮同理,只是方向不同。
Insert
插入到堆的最后一个空位,然后上浮到符合大小关系的位置。
Delete
删除可以简单的将要删除的元素和堆的最后一个元素交换,由于可能破坏堆的性质,所以需要从该位置开始堆化。
Heapify
假设 A 有满足最大堆性质的子堆 B、C,但是 A 的值小于 B(或者 C),性质被破坏,此时将 A 与最大值交换,那么 A、B、C 这三个节点符合堆,但是由于原来的最大值所在的子堆的根被换成了 A,那么这个子堆的性质可能被打破,需要继续向下堆化。(由于另一个子堆没被影响,最大值当然大于它,所以不需要堆化它)
1 | \ \ |
堆化的时间复杂度是 ,其中 是堆的高度。
Build Heap
如上有堆化的过程,但是前提是有已经满足性质的子堆 B、C。
首先将所有元素放入数组,构成完全二叉树。因为叶子节点只有本身,当然符合堆的性质,所以可以从最后一个非叶子节点开始,将它的两个叶子节点作为子堆开始堆化,依次按层从右往左向上堆化,就可以构建堆。
建堆的时间复杂度是 ,堆化每个节点的时间复杂度是 ,其中 是该节点所在的层数。
利用公式
代入 ,得到
所以
Priority Queue
优先队列需要实现 add(item)、getSmallest() 和 removeSmallest() 三个操作。
其中已知数据结构里效率最高的是 BST,然而要用 BST 来实现的话,插入和查找的时间复杂度都是 。将最小堆定义为完全二叉树,且每个节点的值都小于等于其子节点的值,这样最小元素就位于根节点,getSmallest() 的时间复杂度为 ,而 add(item) 和 removeSmallest() 的时间复杂度为 。
add(item) 实现
见 Heap Insert 部分。
removeSmallest() 实现
见 Heap Delete 部分。
Traversals
树的遍历有四种形式:
-
前序遍历(Pre-order Traversal):访问根节点,然后访问左子树,最后访问右子树。
-
中序遍历(In-order Traversal):访问左子树,然后访问根节点,最后访问右子树。
-
后序遍历(Post-order Traversal):访问左子树,然后访问右子树,最后访问根节点。
-
层序遍历(Level-order Traversal):按照树的层次从上到下、从左到右访问节点。
以下的输出以下面这个树为例子
1 | 1 |
前序遍历
1 | void preOrder(Node root) { |
visit 顺序是 1 -> 2 -> 4 -> 5 -> 3 -> 6 -> 7
中序遍历
1 | void inOrder(Node root) { |
visit 顺序是 4 -> 2 -> 5 -> 1 -> 6 -> 3 -> 7
后序遍历
1 | void postOrder(Node root) { |
visit 顺序是 4 -> 5 -> 2 -> 6 -> 7 -> 3 -> 1
层序遍历
1 | void levelOrder(Node root) { |
创建一个优先队列,先添加进 queue 之后再 poll 出来访问,同时添加它的子节点,那么当最后一个节点被访问后且它没有添加新节点进去,就说明树已经遍历完了。
Graph
图和树看起来很像,但任意节点之间都能互联,甚至成环,因此树是图的一种特殊情况。
Graph Representation
有两种常见的图的表示方法:
-
邻接矩阵(Adjacency Matrix):使用一个二维数组来表示图,其中
matrix[i][j]表示节点i和节点j之间是否有边。对于无权图,通常使用布尔值;对于有权图,使用边的权重。 -
邻接表(Adjacency List):使用一个列表来表示图,其中每个节点都有一个列表,存储与该节点相邻的节点。对于无权图,列表中只存储相邻节点的标识;对于有权图,列表中存储相邻节点的标识和边的权重。
1 | class MatrixGraph { |
空间复杂度方面,邻接矩阵需要 的空间,而邻接表需要 的空间,其中 是节点的数量, 是边的数量, 是节点 i 的邻居数量。
时间复杂度方面:
-
addEdge(i, j):邻接矩阵为 ,邻接表为 。 -
hasEdge(i, j):邻接矩阵为 ,邻接表为 -
getNeighbors(i):邻接矩阵为 ,邻接表为 -
整图遍历:邻接矩阵为 ,邻接表为 。
此外查到还有一种思路是 CSR(Compressed Sparse Row),将邻接表压缩成两个数组,一个是 columns 数组,存储所有边的目标节点;另一个是 row_ptr 数组,存储每个节点的邻居表在 columns 数组中的起始位置,若要存储边权,则添加一个 values 数组,存储每条边的权重,对应 columns 数组的位置。
这个设计的空间复杂度为 ,时间复杂度方面:
-
addEdge(i, j):需要重新构建整个数据结构,时间复杂度为 。 -
hasEdge(i, j):需要在columns数组中查找目标节点,时间复杂度为 -
getNeighbors(i):需要根据row_ptr数组找到邻居表在columns数组中的位置,时间复杂度为 -
整图遍历:需要遍历
columns数组,时间复杂度为 。
这个设计唯一的缺点是无法动态添加边,因为 columns 数组是紧凑的,添加边需要重新构建整个数据结构,但在提供优于邻接矩阵的空间效率的同时,提供了与邻接表相同的查询 getNeighbors 时间复杂度,以及比邻接表更友好的缓存性能(内存连续)。
1 | class CSRGraph { |
邻接表在稀疏图中更高效,而邻接矩阵在稠密图中更高效,但实际上测试发现几乎没有差别,可能全存到缓存里面了。
Graph Traversal
图的遍历有两种常见的方法:
-
深度优先搜索(Depth-First Search, DFS):从一个节点开始,沿着一个路径一直向下访问,直到无法继续为止,然后回退到上一个节点,继续访问其他路径。DFS 可以使用递归或者栈来实现。
-
广度优先搜索(Breadth-First Search, BFS):从一个节点开始,先访问所有相邻的节点,然后再访问这些相邻节点的相邻节点,以此类推。BFS 通常使用队列来实现。
两者都需要避免访问已经访问过的节点,以防止死循环,通常使用一个布尔数组或者集合来记录已经访问过的节点。
1 | class DFSHelper { |
Shortest Paths
首先考虑无权图,使用 BFS 就可以找到最短路径,而 DFS 可能会找到一条路径,但不一定是最短的。
考虑有权图的话,BFS 只考虑路径边数不考虑权重,DFS 也不考虑权重,因此都不适用。
Dijkstra’s Algorithm
假设所有边的权重都是非负的,可以使用 Dijkstra 算法来找到最短路径。
如果我们每次都走已知总路径最短的道路,那么归纳下来,最先到达终点的道路就会是总路程最短的道路。
因为已知的任意未到达终点的道路,加上他们对应的下一条边的权重,都比当前已到达终点的道路更长,所以不可能还有其他的道路更短。
实现方法是维护一个优先队列,存储已知道路长度和对应的节点,每次从优先队列中取出总路径最短的节点,更新其相邻节点的路径长度,将其加入优先队列。
A* Algorithm
Dijkstra’s Algorithm 是一种贪心算法,每次选择当前已知路径最短的节点进行扩展,但这意味着最坏情况下,会探索完所有小于等于目标节点的无用路径,会变成一个圆形的探索范围,效率太低。
A* 算法在 Dijkstra’s Algorithm 的基础上引入了启发式函数(heuristic function),通过估计从当前节点到目标节点的距离 ,将 作为优先队列的排序依据,其中 是从起点到当前节点的实际距离,这样可以利用已知全局信息引导搜索。
这取决于启发式函数的设计,CS61B 有两点要求:
-
可接纳性 (Admissibility):不能高估从当前节点到目标节点的距离,否则可能会错过最短路径。
定义: -
一致性 (Consistency):不能违反三角不等式,实际走过的路程不能比估计的路程更短
定义:
一致性比可接纳性更严格,因为两点之间直线最短,如果每一次实际走过的路程都不比估计的路程更短,那么从起点到目标点的实际路程也不会比估计的路程更短,因此一致性包含可接纳性。
由于每次走最短的,假设 为实际全长, 和 为已知长度,因为 和 ,所以在 走完之前最后必有 ,此时 ,可靠。
Minimum Spanning Trees (MST)
最小生成树是用于连接图中所有节点的树,且边的总权重最小。
Cut Property
将图分成两个部分,那么连接这两个部分的最小边一定在最小生成树中。
假设连通加权无向图中有一个割将图分为两部分,且边 为最小割边不在最小生成图 中,那么 中必定存在一条边 连接这两部分,且 ,将 替换为 后得到的生成树的权重不大于 的权重,因此 不是最小生成树,矛盾,所以边 一定在最小生成树中。
Cycle property
以下有参考 环定理
在图中形成一个环路,那么环路中权重最大的边一定不在最小生成树中。
假设边 是环路中权重最大的边且在最小生成树 中,那么去掉边 后,生成树被分成两部分,则环路中必定存在一条边 连接这两部分,且 ,将 替换为 后得到的生成树的权重小于 的权重,因此 不是最小生成树,矛盾,所以边 一定不在最小生成树中。
Prim’s Algorithm
从一个节点开始,逐步将相邻的最小边加入生成树,直到所有节点都被包含在生成树中。
在具体实现中,使用一个优先队列来存储当前生成树的边,每次从优先队列中取出最小边,检查其连接的节点是否已经在生成树中,如果不在,就将其加入生成树,并将该节点的所有相邻边加入优先队列。直到生成树包含所有节点或者边的数量达到 。
注意需要维护一个 visited 集合来跟踪哪些节点已经在生成树中。
这里面用到了 Cut Property,因为每次选择的边都是连接生成树和未包含节点的最小边,一定在最小生成树中。
参考 Prim’s Algorithm 的实现。
中文 Wiki 里面那个 “//来源:严蔚敏 吴伟民《数据结构(C语言版)》” 的到底是什么鬼。。看半天才看懂,谁放进来的
Kruskal’s Algorithm
首先将所有边按照权重从小到大排序,然后逐步将边加入生成树,前提是加入该边不会形成环路。
在具体实现中,会先对所有边排序,然后维护一个并查集来跟踪哪些节点已经在同一个集合中,每次考虑一条边时,检查其连接的两个节点是否在同一个集合中,如果不在,就将该边加入生成树,并将两个节点所在的集合合并。直到生成树包含所有节点或者边的数量达到 。
Kruskal’s Algorithm 同样利用了 Cut Property 确保已连接和未连接之间最小边是在 MST 中的,但也用到了 Cycle Property,由于从小到大来选择边,当前加入的边必是环路中权重最大的边,因此不可能加入环路中。
参考 克鲁斯克尔算法
Trie
HashMap 可以存储任意 key,只要它可以产生合适的哈希值,但对于字符串可以使用前缀树。
每个 Node 存一个字符,路径上连接的字符组成一个字符串,所有以该路径为前缀的字符串都在该节点的子树中,在 Node 中标记是否为一个完整的字符串。
最简单的实现是在每个 Node 中存一个长度为 26 的数组,缺点是空间利用率低,如果字符串比较稀疏的话会有很多空位,优点是时间复杂度为 。
还可以用 BST 来在每一层内部代替这个数组,空间利用率更高,但时间复杂度为 ,其中 是该层的已用字符数量。
和 Ternary Tree 差不多。Ternary Tree 提供左中右三个指针,中代表相等字符,跳转到下一层。
或者进一步用红黑树、哈希表来代替 BST 来实现每一层。
这里完全是时间换空间,权衡一下吧。
在下面补充一些找到的变体:
- Radix Tree:和 Trie 类似,但如果节点只有一个子节点,退化成链表,那么则合并这些链表成一个节点,存储整个字符串;同时将每个节点存储的字符改为一个字符串片段,由参数 决定分支数量和分片长度。
TODO: Double-Array Trie:An Implementation of Double-Array Trie,我看力竭了,等以后有机会再看吧。
Double-Array Trie
在双数组
base和check的设计之前,还有三数组的设计,暂未探究历史
双数组的设计节省空间和对 CPU 缓存友好,有 base 和 check 两个数组,分别用于状态转移和状态验证。
base 数组存储每一个节点的下一个状态的基地址,下一个状态的索引为 base[current] + char,其中 char 可以是当前字符的 ASCII 码或者其他编码值。
但仅有 base 数组无法区分不同状态配合不同的值碰巧落在同一个索引的情况,因此需要 check 数组来获取当前状态的前一个状态,如果 check[base[current] + char] 的值等于 current,则说明该状态是合法的,否则说明状态不存在。
为了方便,base[0] 和 base[1] 都忽略,base[1] = 1 作为根节点的基地址,其他元素全部初始化为 0,表示为空。
状态转移方程:
可以参考 datrie
Add
对于字符串,迭代处理每一个字符。
初始 p 为 1。
插入字符时有三种情况:
-
check[self.base[p] + char] == 0:没有冲突,直接插入,找到下一个状态next = self.base[p] + char,设置check[next] = p,然后继续插入下一个字符。 -
check[self.base[p] + char] == p:已经存在,继续插入下一个字符。 -
check[self.base[p] + char] != 0:发生冲突
每次插入一个字符后,p 都会更新为 base[p] + char,继续处理下一个字符,直到字符串的最后一个字符被处理完。
最后可以将 base[p] 设置为负数,表示该节点是一个完整的字符串。
注意后续取值应该是绝对值。
Conflict
冲突时,只能将当前状态 p 的所有子节点都迁移到一个新的基地址 new_base,然后更新 base[p] 和 check 数组。
找 new_base 需要注意所有 new_base + child 都是是空的。
注意要在 new_base 的基础上处理孙子节点的 check 数组,更新为新的父节点 new_base + child。
注意不需要在当前位置往后找,前面可能同样有合适的空余位置。
Search
类似于 Trie 的搜索,初始状态为 base[p] = 1,对于每一个字符,状态为 t = base[p] + char,如果 check[t] != p,说明不存在;否则继续处理下一个字符,直到字符串的最后一个字符被处理完,如果 base[p] < 0,说明字符串存在。
Optimization
很明显缺陷在于发生冲突的时候,需要迁移整个子树,要在数组里寻找空位,因此有思路是利用 base 和 check 的空位分别作为 prev 和 next 指针来维护一个空位链表,这样就可以快速找到空位。
将 check 的空位标为负数,代表不是合法状态而是空位链表节点。
每次 relocate 后,将释放的空位头插入空位链表中。
我的参考AI实现见 https://gist.github.com/z0z0r4/ceb9c7ec98bc8beee4862e09426ea436
Sorting
Selection Sort
选择排序通过遍历数组,取最大值/最小值放到数组的开头/结尾,重复这个过程直到排序完成。
这个过程的时间复杂度是 ,因为每次选择最小值需要遍历整个数组。
Insert Sort
插入排序不找出最大值/最小值,而是将每个元素插入到它之前已经排序好的部分中,直到整个数组排序完成。
如果数组已经基本有序,那么插入排序的时间复杂度接近 ,但在最坏情况下(例如逆序),时间复杂度仍然是 。
查找插入位置可以使用二分查找来优化,但由于插入操作需要移动元素,整体时间复杂度仍然是 。
Heap Sort
由于堆可以从根获取到堆的最大值或者最小值,因此可以按从堆中取出的顺序来排序。
但这样直接处理会占用额外的空间,因此参考 In-place HeapSort 可以直接在数组原地操作,自下而上、从后向前地从每个叶子节点开始构建一个堆,然后在上层将左右堆合并,最后堆化整个数组。然后将堆顶元素与数组末尾元素交换,重新调整堆,直到堆的大小为 1。
时间复杂度为 。
Merge Sort
合并两个未排序的数组很难,但合并两个数组是容易的,时间复杂度为 ,因此通过不断合并数组的两个部分得到整个有序数组。
具体来说,将数组递归的细分为一个个单独的元素,单独的元素是有序的,然后假设有两个有序数组,合并的过程如下:
-
先准备双指针,分别指向两个数组的开头,比较指针指向的元素,较小的元素放入结果数组中,并将对应的指针向后移动一位。
-
重复这个过程,直到其中一个数组的指针到达末尾,此时将另一个数组剩余的元素全部放入结果数组中。
对于长度为 的数组,首先需要从长度为 的两个数组合并,比较 次;然后从长度为 的四个数组合并,比较 次;以此类推,直到从长度为 1 的 个数组合并,比较 次。
1 |
|
Quick Sort
与 Merge Sort 类似,Quick Sort 也是分治法的一种,但它不是将数组分成两半,而是选择一个基准值(pivot),将数组分成两部分,一部分小于等于基准值,另一部分大于基准值,然后递归地对这两部分进行排序。
在具体实现中,如何分区,有两种常见的方法:
-
Lomuto 分区:
用一个指针i指向小于等于pivot的最后一个元素的位置,另一个指针j遍历数组,当arr[j]小于等于pivot时,将i向后移动一位,然后交换arr[i]和arr[j]的位置,最后将基准值放到i + 1的位置。Python 示例 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def quicksort(src: list, low: int, high: int):
if low >= high:
return
pivot = arr[low]
i = low
for j in range(low + 1, high + 1):
if arr[j] <= pivot:
arr[i+1], arr[j] = arr[j], arr[i+1]
i+=1
arr[i], arr[low] = arr[low], arr[i]
quicksort(arr, low, i - 1)
quicksort(arr, i + 1, high) -
Hoare 分区:
用两个指针i和j分别从数组的两端向中间移动,i向右移动直到找到一个大于等于pivot的元素,j向左移动直到找到一个小于等于pivot的元素,然后交换arr[i]和arr[j]的位置,直到i和j相遇。Python 示例 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def quicksort(arr: list, low: int, high: int):
if low >= high:
return
pivot = arr[low]
i, j = low, high
while True:
while i <= j and arr[i] <= pivot:
i += 1
while i <= j and arr[j] >= pivot:
j -= 1
if i < j:
arr[i], arr[j] = arr[j], arr[j]
else:
break
arr[j], arr[low] = arr[low], arr[j]
quicksort(arr, low, j - 1)
quicksort(arr, j + 1, high)
以上我们总是由于没有空位,只能在两侧找到可以互换的元素后,才调换位置。假如 pivot 所在可以空出来,由于它在左侧,可以把右侧的元素 large1 放上去,这样会有右侧会有多余的 large1,同样可以视为空位,继续把左侧的元素 small1 放到右侧,这样左侧又有了空位,继续把右侧的元素 large2 放上去,如此循环,直到左右指针相遇,此时将 pivot 放到相遇的位置上即可。
1 | def quicksort(src: list, low: int, high: int): |
基准的选择直接决定效率,若选中的基准总是最大值或最小值,每次只能分为基准本身和其他元素,那么时间复杂度退化为 ,因此通常会随机选择基准值,或者选择中位数作为基准值。
三数取中法(Median-of-Three)是一种选择基准值的方法,选择数组的第一个元素、最后一个元素和中间元素的中位数作为基准值。
可以和
low位置的元素交换一下。
Timsort
Timsort 是一种混合排序算法,结合了插入排序和归并排序的优点,尤其适用于部分有序的数据。
Run Detection
Run 是一个连续的子数组,满足以下条件之一:
- 递增:
- 递减:
归并排序没法利用部分有序的特性,在这里会先扫描出 run,若长度不足则使用插入排序将其扩展到最小长度 minrun,若严格递减则先反转成递增(注意是严格递减,为了保持稳定性),最后将 run 的起始位置和长度存储到一个栈中。
显然 的选择直接影响归并树的平衡程度,应该让 的结果等于 2 的幂(或者略小于),这样在归并时这棵树才会是完全平衡的。
如果 ,取 会产生 66 个 Run,导致最后一次合并极度不平衡(2048 个元素合并 64 个元素);而取 产生 64 个 Run 则完美平衡。
具体见 Minimum_run_size
Merge Run
有了 run 之后就可以使用归并排序的方式来合并这些 run 了,但实际上 TimSort 并没有在最后合并全部 run,而是在每次添加一个 run 之后就检查栈顶的 run 是否满足合并条件,如果满足就立即合并:
合并两个 run 的时间复杂度是 ,其中 和 分别是两个 run 的长度,空间复杂度是 ,其中 是经过二分查找缩减后的待合并部分的长度,见下文 Smaller Merge Interval。
固定 产生的 run 的数量和长度是固定的,但合并的顺序并不是。
尽可能让长度相似的 run 合并,可以减少合并的总时间复杂度。
以上两个规则,类似于斐波那契数列,由于 ,Timsort 的序列长度增长比斐波那契数列还要快。
已知斐波那契数列的增长是指数级的:
由于序列总长度 是有限的,而栈中每个元素都呈指数级增长,那么栈的最大深度 满足:
Tips: 实际上条件约束是不够的,参见 CPython #67703 和 proving-android-java-and-python-sorting-algorithm-is-broken-and-how-to-fix-it (Web Archive),Python 已经将合并策略切换到 TimSort 的改进 Powersort 了
Merge Space Overhead
原始的归并排序实现不是原地排序,并且它有 的空间开销。有原地归并排序实现,但时间开销很高。为了达到一个中间值,Timsort 的方法具有较小的时间开销和比 N 更小的空间开销。
对于两个相邻的 run 来说,将其中较短的 run 备份一份到临时数组中,然后开始比较,较小的元素放回原数组中,直到其中一个 run 的元素全部放回原数组中,此时另一个 run 的剩余元素已经在正确的位置上,或者可以直接将剩余元素放回原数组中。
具体来说,数组上的分布是
1 | [... A ... B ...] |
如果 len(A) <= len(B),那么 tmp = A.copy()
那么假设 A 有剩余,则
1 | [... A' + B ... empty ...] |
将 A’ 中的元素逐个放回原数组中,直到 A’ 中的元素全部放回原数组中。
1 | [... A' + B ... A - A' ...] |
假设 B 有剩余,则
1 | [... A + B' ... B - B'...] |
此时 B - B’ 中的元素已经在正确的位置上了,不需要再移动了。
若 len(A) > len(B),则 tmp = B.copy(),然后反过来从右往左塞入,同理可得。
Smaller Merge Interval
假设 A 为 [1, 2, 3, 4, 5, 7],B 为 [3, 4, 6, 8, 9, 10],很显然不需要完整的合并 A 和 B,只需考虑 A 中大于 B 中最小元素的部分和 B 中小于 A 中最大元素的部分即可,即 A 中大于 3 的部分和 B 中小于 7 的部分,剩下的部分已经在正确的位置上了。
因此,我们找到 B[0] 在 A 中的插入位置 i,以及 A[-1] 在 B 中的插入位置 j,具体上会二分查找。
Galloping Mode
对于无序数组的合并,确实需要逐个比较,但对于部分有序数据,可以利用单调性跳过大块元素。
例如 A 中元素为 [_ for _ in range(1000)],B 中元素为 [500, 501, 502, 503, 504],在 i, j = 0, 0 的情况下,如果逐个递增,需要比较 500 次才能找到 A 中第一个大于 B 中最小元素的元素,但如果每次比较后都将 i 加倍,那么很快就可以找到了。
假设正在合并 A、B 两个 Run。如果连续从 A 中取走了多个元素(默认超过 MIN_GALLOP 个,默认为 7),说明 A 的整体水平可能远小于 B。
此时进入 Galloping Mode:
-
指数搜索:不再逐个比较 A[i] 和 B[j],而是拿 B[j] 作为目标值,在 A 的剩余部分中进行“飞跃”查找。检查索引为 的元素,直到找到第一个大于 B[j] 的位置。
-
确定范围:将 B[j] 的插入位置锁定在一个区间内:。
-
二分查找:在该区间内使用二分查找精确定位。找到后,可以将 A 中该位置之前的一整块元素批量移动到合并区域。
对于随机数据,飞跃模式可能会多出几次比较开销。因此 Timsort 会动态调整 MIN_GALLOP 阈值:若飞跃成功则减小阈值,使其更容易触发;若飞跃后发现跳过的元素很少,则增加阈值,甚至使其趋向无限大以关闭该模式。
CPython 有关于 TimSort 的源码可以参考 listobject.c 以及实现细节 Original Explanation by Tim Peters
我自己拙劣实现了一份 Timsort,之后 Benchmark 如下,依据是比较次数
-
*sort (Random):随机数据
-
\sort (Descending):降序数据
-
/sort (Ascending):升序数据
-
3sort (3 exchanges):升序 + 3次随机交换
-
+sort (Tail random):升序 + 尾部 10 个随机数
-
%sort (1% replacement):升序 + 1% 随机替换
-
~sort (Many duplicates):多重复值数据(仅 4 种唯一值)
-
=sort (All equal):全等数据
-
!sort (Mixed/Shuffle):随机打乱数据
| Algorithm | *sort | \sort | /sort | +sort | ~sort | =sort | %sort | 3sort | !sort | |
|---|---|---|---|---|---|---|---|---|---|---|
| 512 | My Timsort | 4150 (104.4%) |
512 (100.2%) |
512 (100.2%) |
648 (98.3%) |
3125 (112.8%) |
512 (100.2%) |
735 (112.0%) |
783 (108.7%) |
4150 (104.7%) |
| Built-in | 3976 | 511 | 511 | 659 | 2771 | 511 | 656 | 720 | 3965 | |
| QuickSort | 6934 | 5120 | 5119 | 5859 | 5815 | 5630 | 5359 | 5119 | 6814 | |
| MergeSort | 3984 | 2304 | 2304 | 2354 | 3660 | 2304 | 2514 | 2739 | 3971 | |
| 1024 | My Timsort | 9299 (103.5%) |
1024 (100.1%) |
1024 (100.1%) |
1192 (101.6%) |
6282 (112.8%) |
1024 (100.1%) |
1613 (109.8%) |
1328 (104.1%) |
9331 (104.3%) |
| Built-in | 8983 | 1023 | 1023 | 1173 | 5571 | 1023 | 1469 | 1276 | 8944 | |
| QuickSort | 13868 | 11264 | 11263 | 12923 | 12474 | 12286 | 12288 | 11263 | 15160 | |
| MergeSort | 8978 | 5120 | 5120 | 5173 | 8215 | 5120 | 6344 | 5817 | 8938 | |
| 2048 | My Timsort | 20714 (103.9%) |
2048 (100.0%) |
2048 (100.0%) |
2236 (100.5%) |
12765 (113.2%) |
2048 (100.0%) |
3164 (108.5%) |
2369 (106.9%) |
20705 (103.7%) |
| Built-in | 19938 | 2047 | 2047 | 2224 | 11272 | 2047 | 2917 | 2217 | 19958 | |
| QuickSort | 33714 | 24576 | 24575 | 27055 | 27055 | 26622 | 26517 | 24575 | 32692 | |
| MergeSort | 19930 | 11264 | 11264 | 11329 | 18268 | 11264 | 14757 | 12265 | 19932 | |
| 4096 | My Timsort | 45570 (103.5%) |
4096 (100.0%) |
4096 (100.0%) |
4292 (100.1%) |
25931 (114.2%) |
4096 (100.0%) |
6746 (110.7%) |
4454 (103.3%) |
45473 (103.2%) |
| Built-in | 44013 | 4095 | 4095 | 4289 | 22702 | 4095 | 6092 | 4313 | 44054 | |
| QuickSort | 73575 | 53248 | 53247 | 59877 | 57008 | 57342 | 58079 | 53247 | 66931 | |
| MergeSort | 44025 | 24576 | 24576 | 24655 | 40277 | 24576 | 33407 | 28483 | 43985 |
Counting Sort
基于比较的话,时间复杂度总是 。但如果已知数据范围且范围较小,我们可以空间换时间,使用一个计数数组来统计每个元素出现的次数,然后根据计数数组来构建排序后的结果。
假设数组 A 数据范围为 ,我们可以创建一个长度为 的计数数组 count,其中 count[i] 表示元素 在输入数组中出现的次数。然后,我们可以遍历计数数组,将每个 重复 count[i] 次添加到结果数组中。
但这样会丢失稳定性,可以通过记录前缀和与逆序遍历来保持稳定性,不直接从 count 堆元素的计数构建数组,而是让 count 提供下一个数值为 i 的填入位置。由于是前缀和,因此要想利用应该是逆向遍历。
1 | def counting_sort(items: list) -> list: |
Radix Sort
计数排序 受限于数据范围,如果数据范围很大,不适合计数排序。
但如果是字符串,数字等类型,可以按字符/按位拆分,逐次计数排序,最终得到排序结果。
其中,LSD(Least Significant Digit)方法是从最低位开始排序,MSD(Most Significant Digit)方法是从最高位开始排序。
MSD 很容易理解,先按最高位分桶,然后对每个桶递归地按下一位分桶,直到所有位都处理完了。
但 LSD 的思路比较巧妙,可以理解为是 MSD 的逆过程:
在 MSD 中,如果要最终从 位得到排序结果,则需要知道 位的排序结果来辅佐,以此类推,直到最低位;
反之亦然,如果我们先知道 位的排序结果,那么再按 位进行排序时,就可以得到完整的排序结果了。
这两种办法都会需要一个稳定的排序算法来保证相同位的元素在排序后相对位置不变,通常选择计数排序。
MSD Radix Sort
MSD 看似简单,实则更复杂,需要递归。
注意递归的边界条件,长度为 0 或 1 的数组是有序的,或者当 exp 为 0 时,说明已经没有位可以处理了。
1 | def get_digit(val, exp): |
但实际上上面这个实现浪费很多内存,因为每次递归都会创建一个新的桶数组,并且在合并结果时也会创建一个新的数组来存储排序后的结果。
下面这个实现不在递归中创建桶数组,而是直接在原数组上进行分区。
1 | def get_digit(val, exp): |
LSD Radix Sort
LSD 的实现相对简单,直接从最低位开始排序,每次使用计数排序来排序当前位,直到最大元素的最高位。
1 | def LSD_radix_sort(items): |
Complexity
参考 CS61B 35.-radix-sorts/35.4-summary
- 是最长键的宽度/位数
- 是数组长度
- 是基数
| Algorithm | Memory | Runtime (Worst) | Notes | Stable? |
|---|---|---|---|---|
| Heapsort | Bad caching 61C | No | ||
| Insertion | Fast for small N or nearly sorted | Yes | ||
| Mergesort | Fastest stable sort | Yes | ||
| Random Quicksort | (expected) | Fastest comparison sort | No | |
| Counting Sort | Alphabet keys only | Yes | ||
| LSD Sort | Alphabet string keys only | Yes | ||
| MSD Sort | (best) (worst) |
Bad caching 61C | Yes |
LSD 非常稳定,因为是从最低位开始排序,必须要处理到最高位才能得到结果。
MSD 在最坏情况下,处理到最低位,则和 LSD 一样;若在最好情况下,可能处理完最高位就结束了,则时间复杂度为 ,有剪枝的效果。
但并非 Radix Sort 就一定比基于比较的排序算法快,因为它的时间复杂度还依赖于 和 ,如果 较小或者 比 小,那么基于比较的排序算法可能更快。
此外,对于定长手机号、邮编等短键可以用 LSD,而对于变长字符串等长键则适合用 MSD。
以及,不一定要按位划分,其实可以设定不同的 。对于数字,比如 256 进制;对于字符串,比如两个字符为一个单位, 就是 了。关键在于 和桶的数量的平衡。
Compression
显然数据是可以被压缩的,压缩的极限可以从信息熵角度计算。
未压缩的情况下,字符依赖 ASCII 和 UTF-8 这些编码将字符映射到二进制数字,而这是固定的映射,固定的码长,使得体积很大。
根据统计概率将字符,或者字符串按出现频率重新映射到一个更优的码表,能有效压缩。
Prefix Tree
一串文本如 z0z0r4 被阅读时,可以看间隔区分出一个个文字。而对于一串 00110110 这样的编码,同样需要有规则区分。
可以固定长度来区分,比如固定长度 4 可以区分成 0011 和 0110。可以指定分隔符 1101 区分为 00 和 10。但这样都产生较高的冗余。
前缀树可以有效的解决这类问题。
如果 01 和 011 都作为码字,就没法区分开。但如果它们的前缀不同,例如 01、001、101 和 111 等前缀不包含其他码字的码表,既不需要固定长度,也不需要固定分隔符,就能达到区分的效果。
将字符都放在叶子节点,第 叶子节点,它的权重为频率 ,到根节点的路径长度为 ,则平均码长为 WPL (Weighted Path Length of Tree) 树的带权路径长度
那么如何构建前缀树,才能使得 最小?
Shannon-Fano Coding
将所有叶子节点尽可能按权重对半区分到两部分,自上而下区分出前缀树的左右子树,这样可以构造一棵前缀树,但被认为并不总是最优前缀树。
Huffman Coding
Huffman Tree 相反,是自下而上构建的,每次选取最小权重的两个节点作为叶子节点为兄弟节点,生成一颗二叉树,其根的权重为两个子节点权重之和,以此类推,这样构建出来的树会是最优前缀树。
证明可以参考 OI Wiki 霍夫曼树 正确性证明
以上的内容都是针对单字符的编码,尽可能减少冗余,逼近香农熵
但是再要继续压缩,可以考虑算术编码,或者考虑进一步为多字符赋予更短的编码。
Lempel-Ziv Series
Abraham Lempel 和 Jacob Ziv 在 1977 和 1978 年发表的两篇论文中提出了两种无损压缩算法————LZ77 和 LZ78,分别利用滑动窗口和显式字典来减少冗余。
LZ77
1 | Window pos Preview |
LZ77 不显式维护字典,而是将滑动窗口区间内的字符作为字典,滑动窗口右侧为当前 pos,若有重复则直接记录与窗口右侧的 offset 和重复的 length,以及第一个未匹配字符 next_char。
按照上面示例,LZ77 应该输出三元组 (8, 4, Q)。当 pos 所在字符无法被匹配,或者原文开头,应该为 (0, 0, {next_char})。当匹配到原文末尾,next_char 不存在,代表解码终点。最终返回值为一个 list[tuple[int, int, T]],顺序不能打乱。
编码如上,解码时只需要按顺序按照三元组内 offset 和 length 读取已解码数据,然后每次在末尾加上 next_char。
TODO
LZ78、DEFLATE、LZMA 也许会有 ZSTD?看难度和时间,起码我感兴趣 😄
压缩这方面能探究的也太多了,也许后续会新开一篇记录。
NP 完全性理论预计将在 CLRS 里面再看。