这是 CSAPP Lab 记录的第五弹————CacheLab。
在此放一张在笔记本上跑出来的 Memory Mountain。
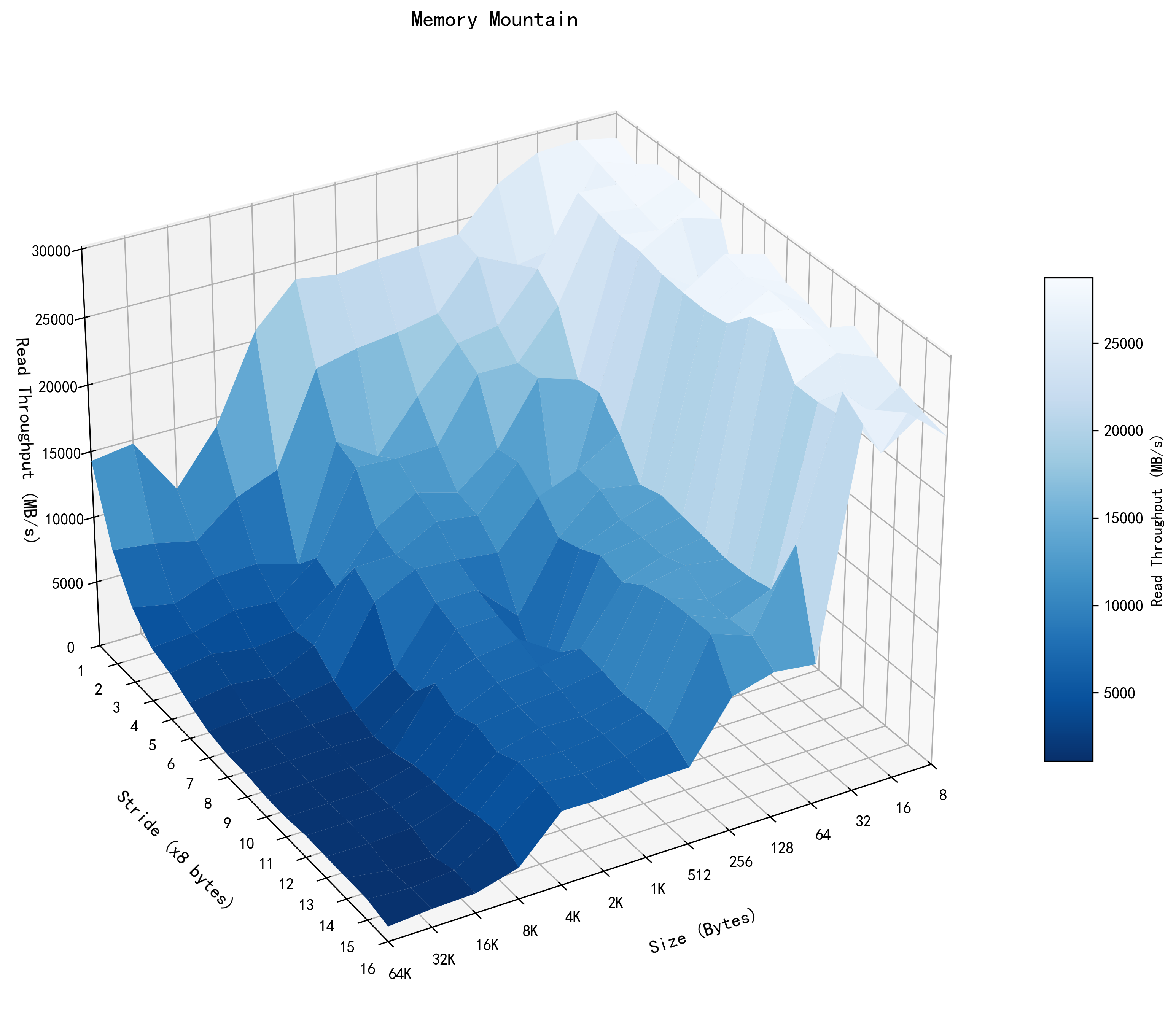
配置如下:
1 | ❯ fastfetch |
PartA 参考自 CSAPP第六章 - 存储器层次结构(Part B 他写的太玄乎看不懂)。
在 Lab Assignments 下载 cachelab-handout.tar。
以下只需要修改 csim.c 和 trans.c 两个文件。
Part A
按照要求完成一个简单的 cache 模拟器。
-
读取用 Valgrind 的内存访问记录生成的
.trace文件,每一行格式为<op> <addr> <size>,其中<op>是L(load)或S(store)或者M(modify),<addr>是内存地址,<size>是访问字节数。 -
读取 CLI 参数构建缓存,其中
-s <s>是 set index 的位数,-E <E>是每个 set 中的行数,-b <b>是 block offset 的位数。 -
模拟访问,其中
L和S代表一次访问,M代表两次访问(一次 load 一次 store)。每次访问都要判断是命中、未命中还是替换。当没有空余行的时候,按照 LRU 策略,淘汰最近最久未被使用的行。(注意替换也算一次未命中) -
按照读取的
traces的顺序模拟对 cache 的访问,统计命中、未命中和替换的次数,传给printSummary函数输出。
参考实现
1 |
|
Part B
完成对 、 和 三种矩阵的转置优化,在 trans.c 中实现 transpose_submit 函数。
最简单的实现当然是直接挨个交换元素:
1 | /* |
参考 cachelab.pdf 中 5.2.1 Performance 说到
For each matrix size, the performance of your transpose_submit function is evaluated by using
valgrind to extract the address trace for your function, and then using the reference simulator to replay
this trace on a cache with parameters(s = 5, E = 1, b = 5).
那么最多有 个缓存行,每行长度为 字节,每个 int 元素占 4 字节,所以每行可以存储 8 个元素。
32*32
对于 的矩阵,我们可以将其分成 的小块进行转置。
1 | void transpose_block(int M, int N, int A[N][M], int B[M][N], int si, int sj, int block_length) { |
结果为
1 | ❯ ./test-trans -M 32 -N 32 |
以上是逐个元素交换,那么假如 A[i] 行映射的组和 B[j] 行的映射的组相同,那么在访问 B[j][i] 时会踢出 A[i] 行存入 B[j],继续交换到 B[j+1] 时也需要读取 A[i] 行得到 A[i][j+1],就会一直互相冲突。
显然如果一次性取出 A[i][j] 到 A[i][j+7] 的 8 个元素存入寄存器中,就算写入 B[j] 有冲突,那么就可以避免上述问题。
1 | void transpose_block(int M, int N, int A[N][M], int B[M][N], int si, int sj, int block_length) { |
结果为
1 | ❯ ./test-trans -M 32 -N 32 |
以下是做完整个实验之后的复盘。在进入 64*64 之前,这里应该思考一下:
- 为什么在 B 竖着写入的时候,B 的每一行之间不会有冲突?
考虑到一个缓存行可以存 32 bytes,也就是 8 个元素,由于 32*32 的矩阵每行有 32 个元素,所以每行占用 4 个缓存行,每 8 行才会将内存映射到同一行中。而分块为 8*8,这决定了分块矩阵内任意两行不可能映射到同一行中,因此自身行之间不会有冲突。
- 什么情况下 B 的行之间可能有冲突?假如有冲突会发生什么?
考虑下方的 64*64 的矩阵,每行有 64 个元素,占用 8 个缓存行,每 4 行就会映射到同一行中。如果分块为 8*8,这决定了分块矩阵内 0~3 行和 4~7 行会分别映射到同一行中,因此在写入 B 的时候,前 4 行和后 4 行互相踢出缓存。
- 剩下的 288 个未命中是怎么产生的?
当分块在对角线上时,A 和 B 的分块的每一行都映射到同一行中,导致大量未命中。
非对角线上的分块应该不会这样。
64*64
的块大小直接套用到 的矩阵上,结果很差:
1 | ❯ ./test-trans -M 64 -N 64 |
将 block_length 改为 16 之后,为什么结果没变…?依旧是 hits:3585, misses:4612, evictions:4580。
这个模拟器是不是有问题.jpg 按道理
block_length从 8 变成 16,misses应该会增加才对
但是对于 的矩阵倒是显著增大了misses,从 288 增加到了 1156
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Function 0 (2 total)
Step 1: Validating and generating memory traces
Step 2: Evaluating performance (s=5, E=1, b=5)
func 0 (Transpose submission): hits:897, misses:1156, evictions:1124
Function 1 (2 total)
Step 1: Validating and generating memory traces
Step 2: Evaluating performance (s=5, E=1, b=5)
func 1 (Simple row-wise scan transpose): hits:869, misses:1184, evictions:1152
Summary for official submission (func 0): correctness=1 misses=1156
TEST_TRANS_RESULTS=1:1156
既然矩阵每四行就会映射到同一行中,那么考虑分块为 ,这样就可以保证分块内任意两行都不会映射到同一行中,结果如下:
1 | ❯ ./test-trans -M 64 -N 64 |
满分要求是 1300 个未命中。
虽然这样也优化了,但缓存行每次读取 8 个元素而只利用了 4 个元素,非常浪费。
经过和 AI 与 参考的殊死搏斗,折磨一晚上,终于跌跌撞撞理解了以下内容
将矩阵 A 和 B 按照 的块进行划分后再对分块划分为 的子块,分别为 ,以及 。
我们可以轻松转置 到 , 到 ,但是还有 和 。
又因为我们需要想办法利用读取 的时候读取到的 (也就是已经读取了 A 的前四行),但是又不能直接写入完 后再写入 (每四行冲突)。
而写入 的时候, 也会被缓存,而 是空的。这样就可以利用 来暂存 的数据。(可以先将 转置到 )
以上是第一步,然后第二步是将 转置到 ,同时将 中的 写入 。
最后,第三步,将 转置到 。
1 |
|
测试得到:
1 | ❯ ./test-trans -M 64 -N 64 |
其实和 32*32 的过程没有太多差别,只是多了个每四行冲突的问题。
实验工具的分析细粒度还是有点低,只有 Summary,也许有需要可以根据 trace 来具体分析吧…
61*67
测试 4、8、16 的分块,可以发现 16 的分块效果最好,通过了…
我还以为又有奇淫巧计,参考前人史料发现寥寥两行
此时 61 不是二次幂,冲突不在对角线上,或许减少?没分析…
Summary
注意:
driver.py是 Python2 写的,得改成 Python3 才能运行。
最终结果:
1 | ❯ python3 driver.py |
这一天下来,问了无数次 AI。实测对于这些内容,训练时应该有 Cache Lab 的语料,AI 可以提供一份能通过的代码,但是没法解释清楚(起码我没听懂),未能给出关键矛盾。也许是语料里也没有分析过程吧…那这篇文章说不定也会被拿去训练?不过可能因为质量太差被清洗掉吧…
说些什么吧!