
这里记录 CLRS 中的基本图算法笔记。
图由顶点集合和边集合组成,写成 ,其中是顶点集合,是边集合。
其中边用两个顶点组成的二元组表示,比如 表示图 中 和 之间有一条边,其中 指向
Graph Representation
有两种表示:
- 邻接表
- 邻接矩阵
这两种设计在各个操作的差别见 CS61B Graph Representation
其中还有 CSR(Compressed Sparse Row)表示,将邻接表压缩到两个数组中,缺点是无法动态添加边,适合静态图的存储。
表示的不同有不同的算法设计,复杂度也大不相同。
22.1-3
有向图 的转置是图 ,其中 。因此,图 就是将有向图 中所有边的方向反过来而形成的图。对于邻接链表和邻接矩阵两种表示,请给出从图 计算出 的有效算法,并分析算法的运行时间。
首先考虑邻接表的,直接按节点获取所有邻居,然后将邻居的边反过来添加到新的图中,时间复杂度为 。
对于邻接矩阵,可以直接转置矩阵,时间复杂度为 。
BFS
这是一份 BFS 实现。
1 |
|
我们需要证明 ,即 BFS 的正确性。
有以下引理:
-
对于任意边 ,有
反证法:假设 ,那么显然可以构造出一条 的路径,长度为 ,假设不成立。
-
对于任意顶点 ,有
假设:
基础情况:当 源顶点加入队列时,,其他节点为 ,满足假设。
那么当顶点 发现 时,有 和 $v.d = u.d + 1。
又因为 ,所以 ,所以 。则假设成立。
-
队列 中为 ,其中 是队头, 是队尾。
证明有两个性质:
首先考虑基础情况,当 中只有一个元素 时,满足 ;
改变队列的只有两种情况:入队和出队。按照代码中的顺序是,先出队 ,然后 成为新的队头,最后 入队替代 成为新的队尾。
归纳步骤:
-
弹出 后, 变成了新的队头,所以要证明性质 1(性质 2 不变):
-
- 有性质 1:
-
- 有性质 2:
-
- 所以 依旧成立。
-
接下里是考虑 入队时,要证明 和 :
-
- 因为 是由 发现的,所以
-
- 引用性质 2 得出性质 1: ,所以 。
-
- 引用性质 1 得出性质 2: ,那么得到 。
那么两个假设依旧成立。
-
-
按照入队顺序, 时,有
按照上面证明,且每个 只会入队一次,所以成立。
但是以上都没约束到 。
用反证法证明,假设存在顶点 使得 。
取 到 的最短路径上的父节点 满足 。
因为 ,那么根据第二点,得出 。
又因为是最短路径,可以得出 。
又因为 ,所以
得到这个式子之后可以具体讨论 在 出队的时候, 的三种颜色:
-
假设 是白色的,那么会赋值为 ,和 矛盾。
-
假设 是黑色的,那么 ,因为 在 出队之前就被发现了。
-
假设 是灰色的,那么取 为发现 的顶点,则 ,又因为 在 出队之前就被发现了,所以 ,所以 ,矛盾了。
综上,说明假设不成立,所以 。
按照 22.2-3 提示,其实不需要区分 BLACK、GRAY 和 WHITE 三种颜色,直接用一个布尔值来表示是否被访问过,
bool visited即可。
广度优先搜索树就是 BFS 过程中,比如由 为 决定到 的距离这样的 连接起来组成的树,从 到达每个节点的距离都是最短路径。
但是路径并不唯一,显然如下图:
graph LR
A((s)) --> B((u))
A((s)) --> C((v))
B((u)) --> D((w))
C((v)) --> D((w))
可以有:
graph LR
A((s)) --> B((u))
A((s)) --> C((v))
B((u)) --> D((w))
和
graph LR
A((s)) --> B((u))
A((s)) --> C((v))
C((v)) --> D((w))
这取决于在遍历 的邻居时, 和 的顺序。
若 在前,显然更先将 的邻居 加入队列,所以 的父节点就是 ,反之亦然。
22.2-6
举出一个有向图 的例子,对于源结点 和一组树边 ,使得对于每个结点 ,图 中从源结点 到结点 的唯一简单路径也是图 中的一条最短路径;但是,不管邻接链表里结点之间的次序如何,边集 都不能通过在图 上运行 BFS 来获得。
想半天没想出来,看了眼答案大彻大悟了,简而言之是贪心
graph LR
A((s)) --> B((u))
A((s)) --> C((v))
B((u)) --> D((x))
B((u)) --> E((y))
C((v)) --> D((x))
C((v)) --> E((y))
无法 BFS 得出:
graph LR
A((s)) --> B((u))
A((s)) --> C((v))
B((u)) --> D((x))
C((v)) --> E((y))
只能得出:
graph LR
A((s)) --> B((u))
A((s)) --> C((v))
B((u)) --> E((y))
B((u)) --> D((x))
或者
graph LR
A((s)) --> B((u))
A((s)) --> C((v))
C((v)) --> D((x))
C((v)) --> E((y))
The Diameter of a Tree
树的直径指的是树中任意两个节点之间的最长路径的长度。
可以很简单的发现直径的两端必然是树的叶子节点。
当确定直径的一端之后,另一端可以简单的从该端开始 BFS 来找到距离最远的节点得到。
有两种实现:
- 两次 BFS/DFS
- DP
两次 BFS/DFS
需要证明从任意节点 BFS 得到的距离最远的节点 是树的直径的一端,以及从 BFS 得到的距离最远的节点 是树的直径的另一端。
树的直径可以有多种,但长度相同。
先证明第一个结论:
假设直径的两端为 和 ,从任意节点 BFS 得到的距离最远的节点为 。
分两种情况:
- 交 的路径于
graph LR
S((S)) --> C((C))
C((C)) --> A((A))
C((C)) --> X((X))
C((C)) --> B((B))
- 不交
graph LR
S((S)) --> C((C))
S((S)) --> X((X))
C((C)) --> A((A))
C((C)) --> B((B))
首先考虑第一种:
由于 ,所以 。
得出 。
那么很明显可以构造一条直径 ,长度为
又因为前提是 是直径,所以 是最长的路径,所以只能得到 ,即可以构造出等长的直径 ,假设成立。
对于第二种情况:
因为 ,所以 。
又因为显然 ,所以
也就是去掉一条 C -> A 的路径,添加一条 C -> S -> X 的路径,显然加上的 S -> X 比 S -> C -> A 更长,那自然比去掉的 C -> A 更长,更别说还有加上 C -> S 的路径了。
所以和 A -> B 是直径的条件矛盾了,情况二不成立。
综合情况一和情况二可知,第一次搜索找到的最远点 必然是树中某条直径的一个端点。
第二个结论非常显然,固定端点 ,从 开始 BFS 得到的距离最远的节点就是直径的另一端。
DP
树的直径也可以通过 DP 来求解。
我的想法是对于树来说,要么直径经过根节点,要么不经过根节点(在子树内)。
如果经过根节点,其直径就是两棵子树的最大深度之和加上根节点。
所以定义 dp[u] 为以 为根节点的子树的最大深度,那么对于每个节点 ,可以通过 dp[u] = max(dp[x]) + 1 来计算出 的最大深度,其中 是 的子节点。
则 ans = max(ans, dp[x] + dp[y] + 1),其中 和 是 的两个子节点。
所以从叶子节点开始,向上合并子树,得到树的最大深度的同时计算出 ans,最终得到树的直径。
参考 OI WIKI 的实现:
1 |
|
这里面将树当作无向图处理,所以会多一个 if (v == fa) continue; 来避免回到父节点。
此外这里写的很巧妙…我自己来写的话,取子树中的最长链和次长链来构成新直径,会显式的写成如下:
1 | static int max_diameter = 0; |
虽然我知道状态转移方程是这样的,但写起来就会变成一堆逻辑判断…很丑陋。
参考中将最长链 + 次长链的信息求和放进结果
d中(也就是我的实现里面的max_diameter),然后在dp[u]中只存储最长链的信息。硬要说的话,可以发现dp中用过的节点的信息是没必要再存着的,我的实现里面唯一的好处就是空间占用略微小了点。
DFS
首先放一份 DFS 实现:
1 |
|
DFS 不维护队列,而是找到邻居就直接递归向下遍历,直到没有邻居了才回退。
BFS 构成一棵 BFS 树,但 DFS 构成的可能是森林(多棵树):
-
无向图:如果是连通图,DFS 总是能一次性访问到所有节点,所以就是一棵树。
-
有向图:可能访问不到某些节点,需要回到
dfs再选取剩下的节点作为起始节点,继续 DFS,直到访问完所有节点。可能有多棵树形成森林。
DFS 的时间复杂度也是 ,因为每个节点和边都访问一次。
可以发现比 BFS 的实现,DFS 的 Vertex 的多了 start_time 和 finish_time 两个属性。这是为了方便引出以下的内容。
以下简称为属性 和 分别表示 的 start_time 和 finish_time。
括号化定理(Parenthesis Theorem):对于任意两个节点 和 ,以下三种情况只有一种成立:
-
和 互不为祖先: 和 没有交集。
-
是 的祖先: 包含 。
-
是 的祖先: 包含 。
也就是不可能存在两个节点的开始时间和结束时间交错的情况。
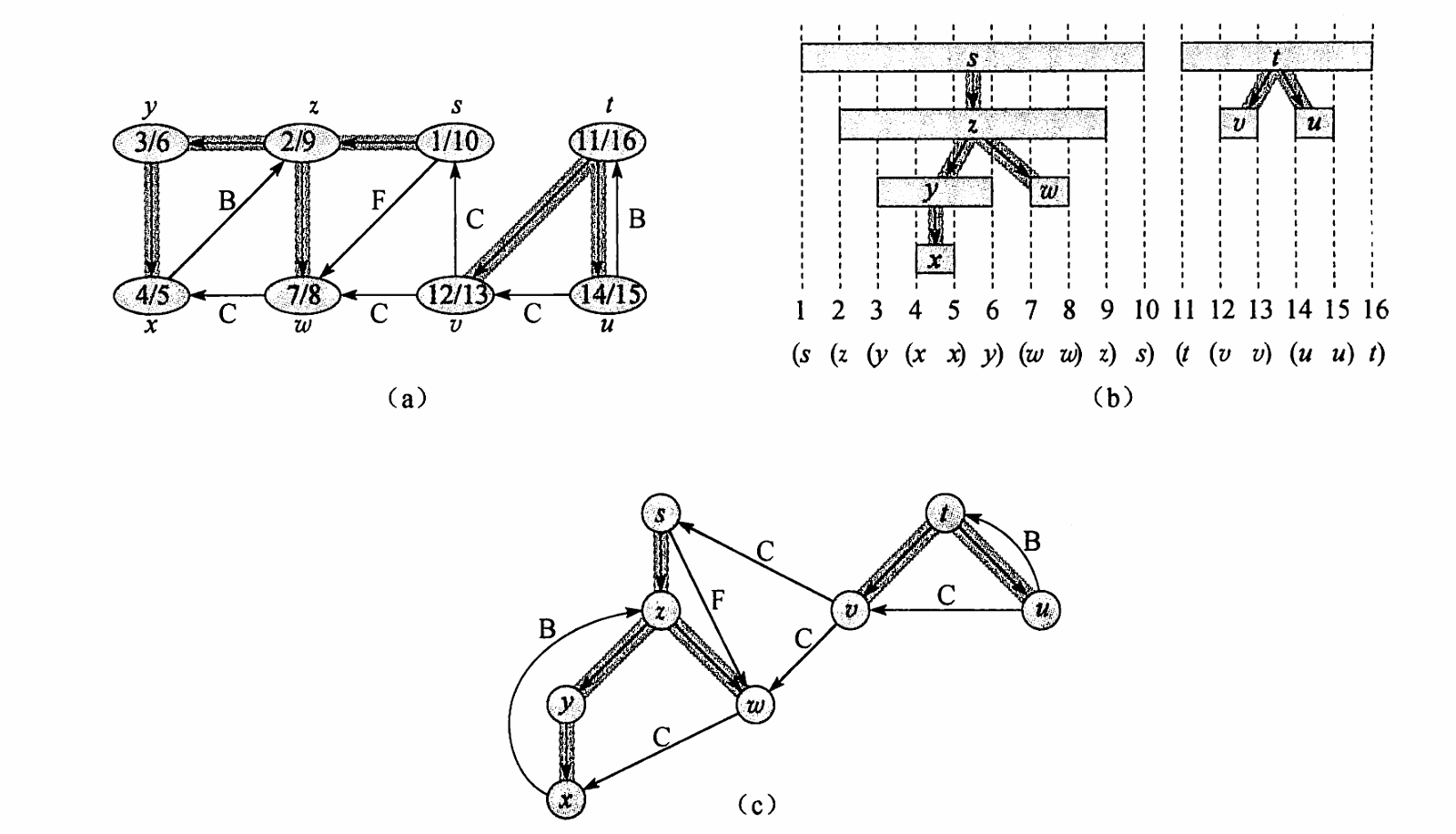
根据如上的三个情况,显然可以推出 Nesting of descendants’ intervals(后代区间的嵌套):当且仅当 是 的祖先时,满足 。
从代码上观察递归嵌套,和时间戳截取的时机可以很容易观察得出,不证明=-=。
若 是 的后代,有另一个性质——White-path theorem,白色路径定理:
是 的后代当且仅当在 的 start_time 时,存在一条全部由白色节点组成的路径从 到 。
注意是充要条件。
先证明 是 的后代 在 的 start_time 时,存在一条全部由白色节点组成的路径从 到 :
考虑 设置 的 start_time 时,显然 还是白色的(没有置灰),所以成立。
当 时,假设 是 的任意后代,又因为满足 ,所以有 。节点 在 才置灰,前提说此刻是 ,所以任意后代 都是白色节点,构成了一条从 到 的白色路径。
反过来证明,条件是存在白色路径。
假设 不是 的后代,那么取 和 的路径上的最后一个后代为 ,则满足 。
因为 不是 的后代(也不是 的后代)且存在边 ,那么 应该在 之后、 之前被访问到,所以 ,符合括号化定理中 是 的后代的情况,矛盾了,所以 必然是 的后代。
所以有白色路径相通则 必然是 的后代,反之亦然。
DFS 本质是贪心的,那么有能连通的白色路径当然会成为后代,成为了后代当然得有连通的白色路径…读的力竭了
根据节点间的跳转,节点间的边分类可以有:
- 树边(Tree Edge):DFS 过程中访问到一个未访问过(白色)的节点时的边。(即发现节点的边)
- 前向边(Forward Edge):由祖先节点连接后代节点。
- 后向边(Back Edge):由后代节点连接祖先节点。(注意,自身连接自身也算后向边)
- 交叉边(Cross Edge):连接两个不具有祖先关系的节点。(可能跨树,也可能在同一棵树中)
书中给出了根据颜色判断边的类型:
- 白色节点:树边
- 灰色节点:后向边
- 黑色节点:前向边或交叉边(后续根据时间戳区分)
对于无向图来说,只有树边和后向边,因为无向图中不存在前向边和交叉边。
首先考虑前向边,考虑有向图的情况下,假设 是前向边,必有两条路径使得 连通,比如先遍历了一条例如 的路径,到达 后发现边 反向无法连通,所以回溯到 ,之后又遍历了一条 的边,发现 已经是 的后代了,又回溯到 ,所以 就成了前向边。
然而无向图不存在方向,也就是在第一次发现 之后,第二条路径 <-> <-> 是通的,所以会一直形成树边直到回到 ,不存在前向边,只会后代节点连接祖先节点形成后向边。
交叉边也来自于有向图的单向性质。若 是交叉边,那么 DFS 先访问了 ,之后又访问了 ,而 有指向已被访问的节点 的边。倘若 和 之间的边是无向边,那么显然在访问 的时候就会访问 ,所以 和 之间的边不可能是交叉边。
依旧归于贪心。
22.3-4 和 BFS 一样提示不需要区分黑色、灰色和白色三种状态,直接用一个布尔值 visited 来表示是否访问过即可。
中文版又错了,写错了行数,删第 8 行写成了删第 2 行…前面也有不少错误。比如无权图写成无向图。
22.3-7 提示 DFS 可以用栈来实现,消除递归。显然只要将父节点入栈,回溯时出栈即可。
1 |
|
每次循环都获取栈顶顶点的邻居列表,如果没有新邻居(
pushed_new == 0)入栈了,说明当前节点的所有邻居都访问过了,则出栈,否则将新邻居入栈,并记录这是第几个邻居。
22.3-5 中有以下边 和时间戳的关系:
- 树边或前向边: ( 是 的后代)
- 后向边: ( 是 的后代)
- 交叉边: ( 已经被访问过了)
Topological Sort
拓扑排序指的是将所有节点线性排序,使得对任意边 , 在排序中排在 之前。
观察可得必须是有向无环图,如果是有环图显然会冲突。
按照图中观察也可以猜出是先 DFS 然后按照 finish time 的逆序来排序的。
通过以下两个证明来得出 DFS 的 finish time 的逆序就是拓扑排序:
-
有向图是无环的当且仅当没有后向边。
以下证明的都是逆否命题:有环当且仅当有后向边
假设有后向边 ,那么 是 的祖先,其路径与边 形成一个环。
假设有环,假设其第一个被发现的节点为 ,则有 和环上剩下的节点构成的一条从 到 的白色路径,则 是 的后代。而后代指向祖先的边就是后向边。
-
有向无环图中,对于任意边 ,在 DFS 中 。
探索 时,考虑 的三种颜色:
不能为灰色,否则 是 的祖先,形成后向边,与上面的证明矛盾。
当 为白色,则 是 的后代,按照后代嵌套的性质,。
当 为黑色,则 在 之前就已经置黑,显然 。
则 成立,即 。
Strongly Connected Components (SCC)
强连通分量(SCC)指的是一个最大节点集合 ,使得对于任意 ,都有 到 的路径和 到 的路径。
比如成环的节点集合可以是 SCC,多个环粘在一起则是一整个 SCC(单个节点也可以是)。
如上所说,图 可以被转置为 ,其中 。
观察到 中的 SCC 在 中也是 SCC。
那么书中给到的寻找 SCC 的算法是:
-
在 上运行 DFS,记录每个节点的
finish time。 -
转置图 得到 。
-
在 上按照
finish time的逆序运行 DFS,每次 DFS 访问到的节点集合就是一个 SCC。
注意这里的逆序指的是最外层循环遍历节点的顺序,按照这个顺序去进入
dfsvisit,而不是在dfsvisit内部按照finish time的逆序去访问邻居。
如何证明正确性?
观察下面的图片就可以发现正确性,先 DFS 记录 finish time,之后转置图,任选一个节点进去 dfs_visit 就会发现只能访问到节点所在的 SCC,无法访问的其他的 SCC
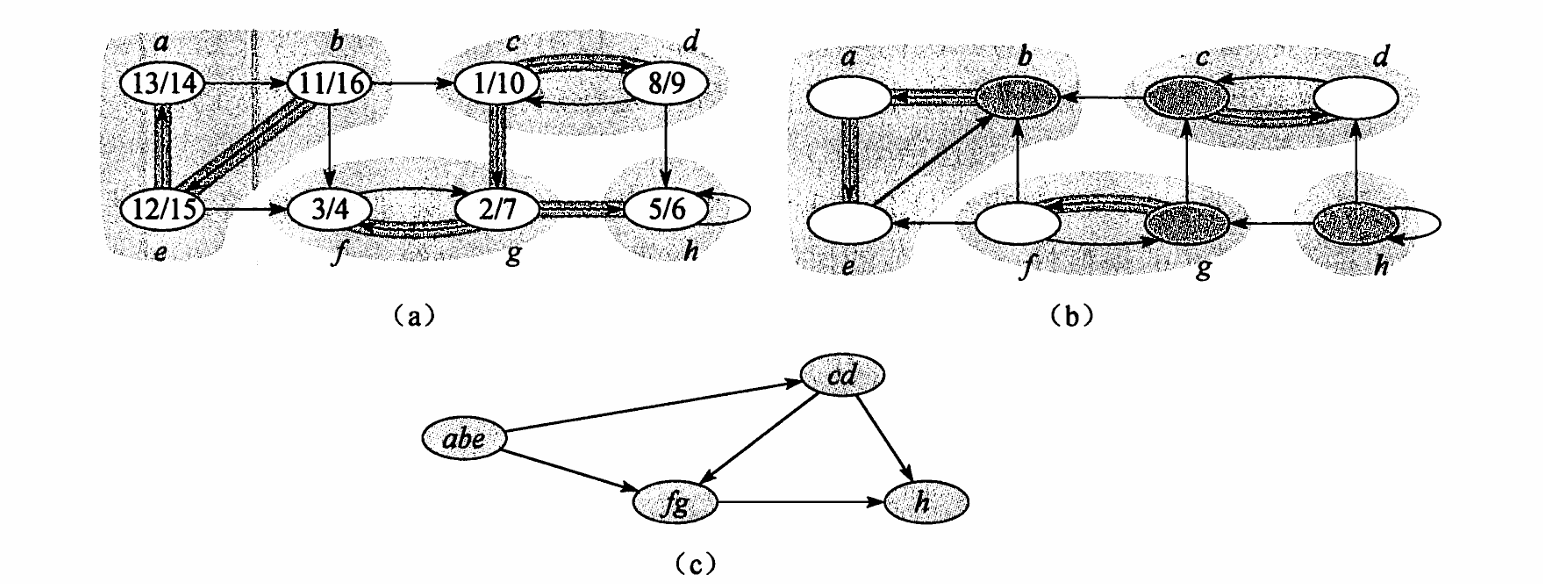
以下三个步骤证明正确性:
-
图 中有两个不同的 SCC 和 ,使得 ,,假定存在路径 ,则不存在路径 。
反证法:假设存在路径 ,则 和 是连通的,合起来是同一个 SCC,矛盾了。
定义为 中所有节点的
finish time的最大值。定义为 中所有节点的
finish time的最小值。
-
图 中有两个不同的 SCC 和 ,使得 ,,存在边 ,。
覆盖两种情况:
-
:则 中第一个被发现的节点 必然有一条白色路径通往 和 中的所有节点,则 (除去 自身) 和 中的所有节点都是 的后代。根据后代嵌套区间,有 。
-
:则 中的所有节点在 第一个节点被访问时还是白色的。又因为 没有通向 的边( 只能从 通向 ),所以 中的最后一个节点 结束时, 中的所有节点都还是白色的,所以 。
-
综上,第一次 DFS 遍历时,有边 使得 通向 的情况下,。(晚指向早)
那么接下来证明转置后是早指向晚:
-
图 中有两个不同的 SCC 和 ,使得 ,,存在边 ,则 。
由于 ,那么存在 ,根据上面的结论,,。
所以,在转置后变成了早指向晚。
为了获取 SCC,只需要在第二次 DFS 时,从最晚的节点开始 dfsVisit,则其所在的 SCC 的 是最晚的,又因为早指向晚,所以无法从该节点访问到其他更早的 SCC(更晚的已经被访问过了),只能在这个 SCC 呢。
其实就是按拓扑排序的次序。
说些什么吧!