关于 CMU 15-445 Project 0 Primer,记录几个概率性数据结构。
最近一直在看 CMU 15-445 的 YT 课程视频(B站中文精翻)和完成 BusTub 项目。我觉得课程很好,但视频内容经常需要辅助 AI 具体了解才能看懂,Bustub 项目也非常有挑战性好难。总体上是我太菜,课程非常好。
Andy Pavlo 和他的助教们,每年都会更新 BusTub 的内容(因为 BusTub 是公开的,大概是为了避免抄袭、以及提前完成?),按 Git History 是秋季(暑假)更新 BusTub,春季基本不会动。
以下实现了 2025 和 2024 的 Project 0 Primer 的数据结构:
以及最基础的 Bloom Filter 和可扩展的 Scalable Bloom Filter。
由于 Trie 和 Skip List 感觉会比较麻烦,今天先不写。
Bloom Filter
布隆过滤器可用于检索一个元素是否在一个集合中,具有空间效率高和查询速度快的特点,但存在一定的假阳率,取决于哈希函数的数量和过滤器占用空间的大小。
若用哈希表,可以精确的判断,原因在于会处理冲突的情况。但如果不处理冲突,只要有一个元素映射到某个位置,就设置这个位置被占用,那么其他映射到相同位置的,不存在的元素就会被误判,这就是假阳率的来源。
那么进一步改进,则可以使用多个哈希函数,只有当所有对应位置都被占用时,才认为元素存在,以降低假阳率。
插入和查询的时间复杂度都是 ,可惜缺陷在于无法删除元素,以及假阳率的存在(但这是不可避免的,Andy 也总是在课程里面说没有免费的午餐)。
对于一个实际不存在的元素,当其每个对应的 个位置全部都刚好被置为了 1 时,就会被误判为存在,又因为假设哈希函数是均匀分布的,所以可以独立考虑每个位置被置为 1 的概率。
其中 是 Bloom Filter 的位数组大小, 是插入的元素数量, 是哈希函数的数量。
插入一个元素时,对于一个特定位置,被单一哈希函数选中的概率是,
没有选中的概率则是
插入一个元素需要经过 个哈希函数的置 1,所以某个位置仍然为 0 的概率是
那么插入 个元素后,某个位依然为 0 的概率是
根据重要极限,
所以对于较大的 可以近似为(在指数补一个 ):
所以某个位置被置为 1 的概率是
则误判时, 个位置都被置为 1 的概率是
一般来说,预期元素数量 和 位数组大小 是给定的,那么应该向最小化 的方向找出 的最优解。
取 ,则 ,代入上式:
实质上是求 的最大值,使得 最小。
易得 在 处取得最大值,此时 。
所以
当然在实际应用中, 只能取整数
Bloom Filter 无法自动拓展,随着元素数量的增加,假阳率会逐渐升高。为了解决这个问题,可以使用 Scalable Bloom Filter,它通过维护多个 Bloom Filter 来实现动态扩展。
当一个 Bloom Filter 的容量达到预设的阈值时,Scalable Bloom Filter 会创建一个新的 Bloom Filter,并将新元素插入到新的 Bloom Filter 中。
查询时,Scalable Bloom Filter 会依次查询所有 Bloom Filter,只要其中一个 Bloom Filter 返回存在,就认为元素存在。
创建新 Bloom Filter 时,可以设置一个缩放因子 ,每次创建新 Bloom Filter 时,其大小是前一个 Bloom Filter 的 倍(以免 filters 数量线性增长,查询时要遍历检查的 filter 太多)。
以下是 Bloom Filter 的实现(完整见 Bloom Filter Gist):
1 | template <typename T> |
Count-min Sketch
上面的 Bloom Filter 是用来判断元素是否存在的,而 Count-min Sketch 则是用来估计元素出现的次数的。
CMU 15-445 的课程视频里面提到的一个例子是网站 IP 访问量估计,其他情况类似。
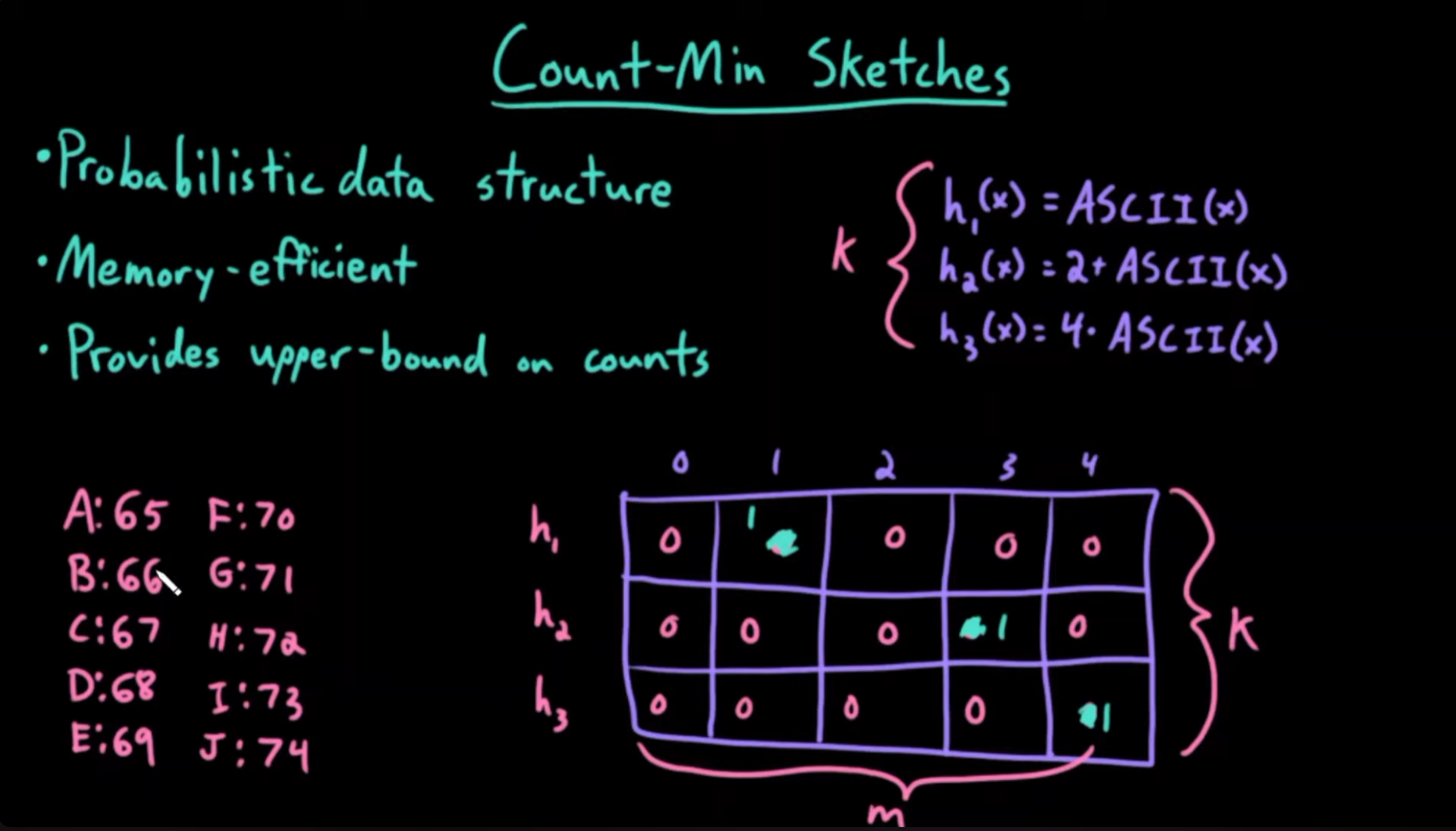
Count-min Sketch 使用一个二维数组来存储计数器。
假设二维数组的行数为 ,有 个哈希函数,每个哈希函数对应一行;列数为 ,哈希值取模 。
每个元素添加时,计算 个哈希函数映射到不同的行,取其计算出来的列索引,在对应位置的计数器 +1。(总共更新 个计数器)
查询元素时,如上找到 个计数器,取其中的最小值作为元素添加的次数估计。
很显然,由于不同元素可能更新同一个计数器,计数器的值必然是等于或者高估的,所以取所有计数器的最小值作为估计值,是最接近真实值的。
直觉上,二维数组的大小直接决定误差大小。准确的来说,CM Sketch 的误差由两个参数来描述:精度误差 和错误概率 。
精度误差指的是估计值与真实值之间的允许误差比例,例如 表示估计值与真实值之间的误差不超过 1%。
错误概率 则是指估计值超过精度误差的概率,例如 表示有 5% 的概率估计值会超过精度误差。
-
宽度
-
深度
此处不讨论 和 的公式哪来的,
看不懂
以下是 Count-min Sketch 的实现(完整见 Count-min sketch Gist):
基于 Primer 改的,有
TopK的功能,以及 thread-safe 实现Insert
1 |
|
1 |
|
HyperLogLog
HyperLogLog 与以上两种的生态位也不同,目的是估计一个集合中不同元素的数量(基数估计)。
若要精确统计,则需要记录所有元素以供查询是否重复,但这会占用大量内存。
考虑一个抛硬币的情景,可以发现当第四次才抛出正面,前面三次都是反面时,那么这个序列的概率是 。那么逆向过来可以理解为:要想得出这个序列,平均需要抛 16 次硬币。
那么对于元素取 Hash,记录所有元素的前导零的最大值 ,由于特定比特位只有 0 和 1 两个可能,就可以估计出不同元素的数量大约是 。
但是很显然,单次伯努利试验的随机性太高,容易因为某个极端哈希值(例如一开始就连续出现很多个 0)导致估算结果出现巨大偏差。
为了降低误差,HyperLogLog 将哈希值分成 个桶(有 个位用于分桶),每个桶记录前导零的最大值 (前导零不算用于分桶的 位)。
计算 HyperLogLog 的估计值时,先计算每个桶的 的估计值的调和平均值,乘以总共 个分桶。
实际上看,会再乘一个修正因子 来调整估计值,具体的修正因子取值可以参考 HyperLogLog Wikipedia 的相关内容。
HLL 相比 LL(LogLog)算法的改进:LL 计算几何平均值,而 HLL 则是计算调和平均值,这样可以更好地抵消极端值的影响。
其中 就是分桶的前导零的最大值, 是分桶的调和平均值, 则是最终的估计值。
实现如下:
1 |
|
结果为:
1 | Estimated cardinality: 1.11156e+08 |
哈希函数的质量很重要,用之前 Bloom Filter 的那个 D. E. Knuth 的简单 Hash 比
std::hash的误差会大不小。但不想花时间在处理哈希上,之前的就没改。
此外,如果考虑时间窗口,比如通过时间段内的访问用户数量(日活、月活),可以维护多个 HyperLogLog 实例来实现时间窗口的滑动,每个实例对应一个时间段。当时间窗口滑动时,旧的实例被丢弃,新的实例被创建。
Cuckoo Filter
Cuckoo Filter 和 Bloom Filter 类似,但是支持删除元素,其空间占用效率应该高于 Bloom Filter。
Cuckoo 是布谷鸟的意思(出生的幼鸟踢开其他鸟蛋),其思想和 Cuckoo Hashing 类似,处理冲突的方式是“踢出”与插入项冲突的项,直到找到一个空位或者达到最大尝试次数。
为了支持删除,就需要存元素的信息。但同样,存完整信息就变成哈希表了,所以是部分信息。
与 Cuckoo Hashing 不同的是,Cuckoo Filter 不是存储元素的完整信息,而是存储元素的指纹,或者叫标签 Tag,都可以,以节省空间。
此外,Cuckoo Filter 的一个 index 对应的是一个较小的 bucket,例如四个 Slot 存储 Tag。
Cuckoo Hashing 利用两个哈希函数和两个子表来存储元素,而 Cuckoo Filter 的每个元素对应的是根据元素的 Hash 值计算的一个 Tag,以及两个 index。Cuckoo Hashing 确认 index 的时候是直接计算 和 ,而 Cuckoo Filter 没有存储完整的元素,只能根据 Tag 和一个 index,来计算出 alt_index。
注意:index 和 alt_index 的 alt 只是相对与 index 而言的,它们之间是一个异或计算,有自反性。可以从任意一个 index 和 Tag 计算出另一个 index。
其中 是元素的 Tag, 是桶的数量(总是二次幂), 是 index,那么 的计算方式是:
Tag 的计算公式通常是取元素的 Hash 值的某些位,例如:
注意这里和一般哈希表不同,不通过取模而是位与来取 index,原因是需要自反性,而取模会破坏自反性。
(From Gemini,我最开始实现的时候取模了,然后一直没领会到和 Cuckoo Hashing 不同,要利用异或的 的性质来计算 alt_index)
查询时,应该检查 index 和 alt_index 对应的桶中是否有 Tag 匹配。
插入时,首先计算 index 和 alt_index,如果其中一个桶有空位,就直接插入;如果两个桶都满了,则开始循环:随机选择一个桶中的随机一个 Tag 踢出,然后将被踢出的 Tag 试着插入到其对应的另一个桶中,若成功则结束,若失败则继续循环这个过程,直到找到一个空位或者达到最大尝试次数。
删除时,计算 index 和 alt_index,检查两个桶中是否有匹配的 Tag,如果找到则删除其一。
必须是其一,不能都删掉。假设有相同 Tag 和 index 的两个元素 A 和 B,则其应该位于于 index 和 alt_index 不同桶中,如果删除了 A 的 Tag 之后还去找 alt_index 的桶去删除 B 的 Tag,则会误删 B。
反之,如果删除了 A 但是没有删除 B 的 Tag,当然查看 alt_index 时看到了相同 Tag 的 B,A 仍然会被误判为存在,符合预期。
考虑上面 A 和 B 的极端情况,如果没有 bucket,此时有 C 也符合情况,那么插入就会失败,因为只有 index 和 alt_index 两个 Slot,互相踢出直到达到最大尝试次数,仍然无法找到空位。这就是需要 bucket 的原因,通过增加常数时间的开销(遍历较小的 bucket),避免在 Filter 明明还要很多空余空间的情况下,因为布谷鸟的机制被迫无法 Add。
此外,更极限一点,还可以增加一个 Victim,临时记录添加失败的元素的信息。在有删除时,最后检查是否有 Victim,如果有则尝试重新插入 Victim,如果成功则清空 Victim,如果失败则继续保留 Victim。也就是从 变成 ,多了一次机会。
记得在添加和查找操作都要额外检查
Victim
Bucket 的大小为 4 是论文中实践出来的最优解,详情见论文 Cuckoo Filter: Practically Better Than Bloom 或者 doi:10.1145/2674005.2674994 的 Optimal Bucket Size 的部分,作者有尝试过 1、2、4、8,最终推荐 4。
Redis 提供有 CF 命令,见 DocsDocs → Develop with Redis → Redis data types → Probabilistic → Cuckoo filter
官方实现见:efficient/cuckoofilter
一份我觉得正确的实现:z0z0r4 - Cuckoo Filter
1 |
|
TODO: Cuckoo Hashing
说些什么吧!